Brian Ayres:
Good morning everybody, thanks for joining our summer webinar series on KTM Learning Server. We’ll do a quick info about RPI. We’ve been working with Perceptive for about 16 years, our imaging practice has grown, we’re up to about 20 members now. The larger portion of our practice is actually a Lawson practice, we have about 70 consultants on the Lawson side. Our main offices are in Baltimore, Tampa, and Kansas City where I’m actually at today.
As far as the work we do at Perceptive, pretty much everything. We do eForms, iScript designs, workflow designs, redesigns, upgrades, which we’ve been doing a lot of recently, as I’m sure you’re aware if you use Perceptive. Health checks, security audits, migrations, we also work in the clinical and HL7 space. That’s a little bit about RPI.
A little bit about myself. My name is [Brian Ayres 00:01:08], I’m a senior Kofax consultant at RPI. I’ve been with RPI for about 11 years. The majority of that time I’ve been working with the Perceptive tools as well as Kofax. It’s kind of given me a unique view into the Kofax software, I’ve seen it grow over the years. One of their bragging points usually for their sales is how much money they put into their research and development and I can definitely verify that that’s true. We’ve seen the software grow a lot over the last couple years which has made this smart learning a very powerful tool.
Okay, so now we’ll jump into the good stuff here. Today we’re going to take a look inside the Black Box that is smart learning and data extraction. A lot of you have probably seen Kofax demos or have seen data capture demos. Some of you may already own the software and you do demos, or you see it work as an end-user. It just magically works. We want to show how to set up your projects to maximize the smart learning. We’ll actually get into some technical stuff to see within Project Builder what settings you want to have set up, what locators you want to use to accomplish this. We’ll take a look at that functionality.
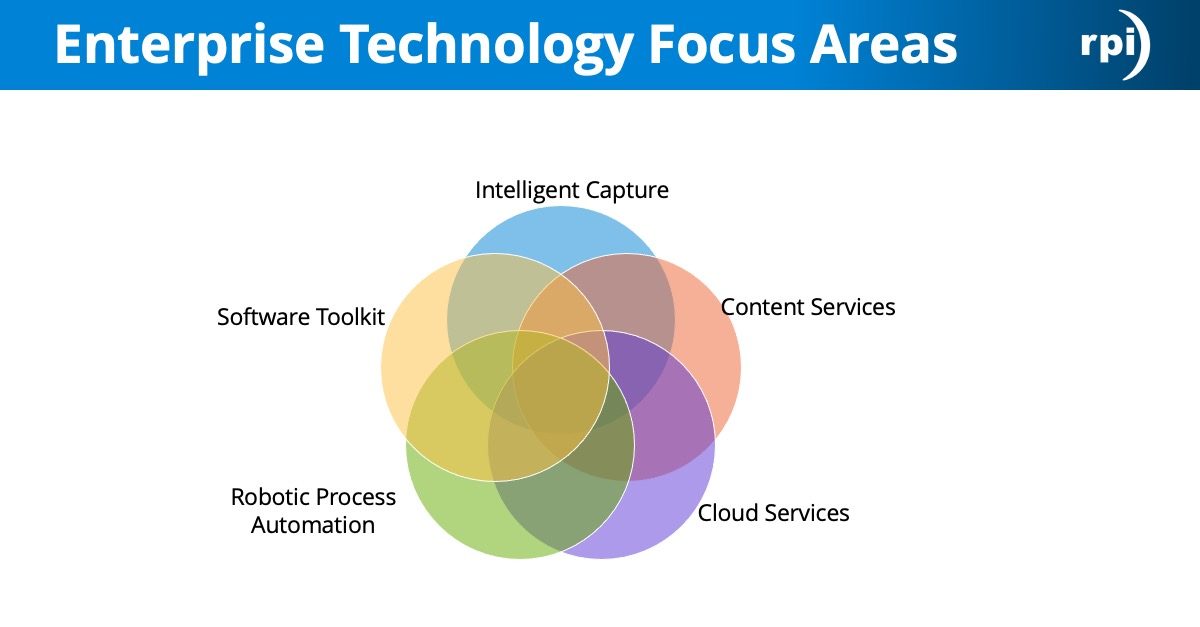
Before we get into that, I want to talk a little bit just about the Kofax software, the different pieces of Kofax. There’s three main pieces I want to discuss. The Kofax Transformation Modules is the smart learning portion of it, so that’s where we’re going to spend a lot of our time today, but the Kofax Capture piece is basically the front end scanning where you do have a scanner hooked up and you scan in documents. Also if you’re going to be ingesting emails, things like that, that all happens in the capture portion of Kofax. Then the Transformation Modules is where all the smart learning happens, where you design your validation forms, you build in all your field validation, and formatters.
Those two pieces usually hand-in-hand. When we install a Kofax solution, typically our customers get installed Kofax Capture and Kofax Transformation Modules, which I’ll probably be calling KTM the rest of the way here, so if I say KTM, it’s Kofax Transformation Modules.
The Kofax Total Agility though, I did just want to mention this … It’s a newer platform for Kofax, so a lot of the newer installations are using Total Agility. It basically allows you to have some more workflow and business process capabilities with inside Kofax. It allows you to do mobile capture and a lot of advanced analytics around business processes. The newer installations are going to have Kofax Capture and Kofax Transformation Modules kind of built into Total Agility, so they’re modules within that application. Or Kofax Capture and Transformation Modules can stand alone as well. I just wanted to mention that.
The typical lifecycle of an invoice or document through Kofax … You can use Kofax for many different types of documents. I’m going to specifically be talking about invoices today and use that kind of as my example. This is a typical flow of data that would come through Kofax. You have your scan step, which is going to be manual if you’re actually using a physical scanner. If you are ingesting documents through email or file imports, or even fax, if people still fax, they can be ingested through the scan module as well. Those would be kind of automatic steps where you’d have an email box that’s monitored to bring documents in.
After they come into Kofax, they got onto the KTM server. That’s really where all the magic happens. All the data gets extracted, all the rules and locators that you’ve built are applied. That is an automated step. Nobody’s touching it when it’s going through that step.
The validation module, that’s where your end-users, your validators, we’ll call them, will go in and actually validate the data that gets extracted off of the invoices or documents. We’re going to see how they can actually make the system smarter as well through that step, and flag things for learning. After that step, there’s another automated step to the knowledge base learning server, and that is where the system will get smarter over time. It will learn the invoice samples that you’re running through Kofax. The next time a batch gets scanned in, you’ll have the advantage of that knowledge that was added to your knowledge base.
Then the last step is export. That’s where data’s passed off to any other applications that need it. If you have any third-party applications, another ERP, document imaging, reporting warehouses, things like that … we can build exports to connect to those. The export in Kofax is very flexible. We’ve done SOAP and REST web service interfaces, flat file exports, database updates. You can really interface with any application that allows you to ingest data. We can format it the way that that application needs it.
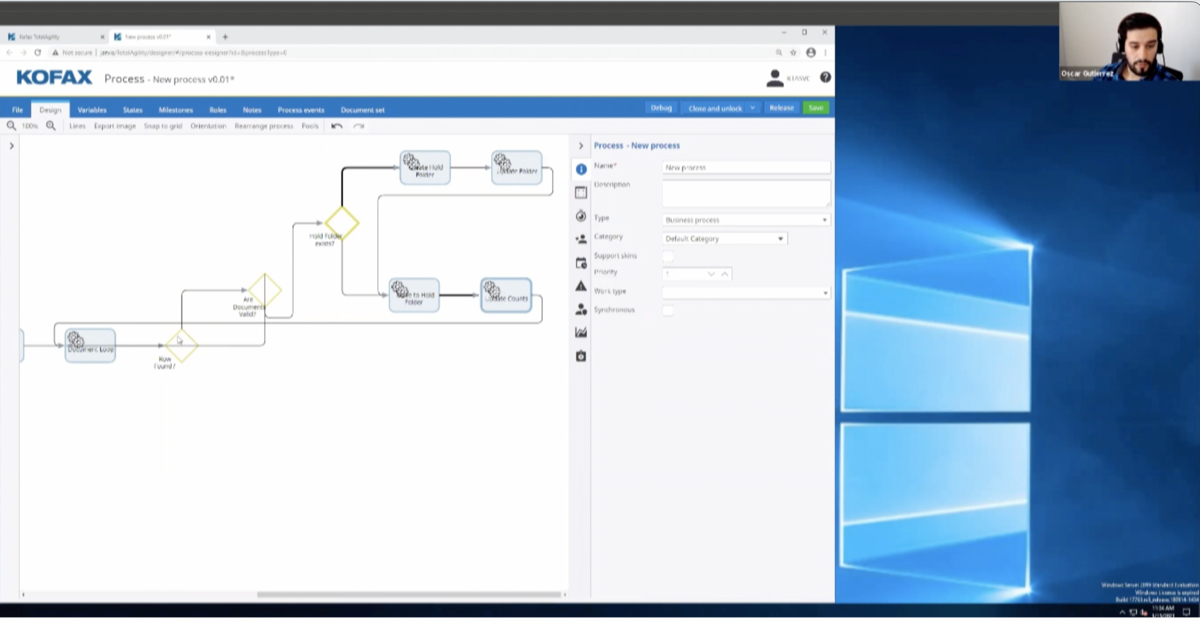
Next I wanted to show you a sample validation form real quick. I think probably a lot of you are a little bit familiar with Kofax, but I want to show you what a validation form looks like that we’ve designed. This was actually for a PO solution. We have basically all of our PO header data, our vendor remit to data, the invoice header information that we’re able to extract. Any discounts, then exceptions or comments that need to be added to the invoice. We actually have two forms set up here. This is a PO solution as I mentioned, so we have a PO header, which is everything we’re seeing here. Then we have a PO line matching tab as well where you can actually do all the PO line matching.
The one thing I did want to mention on this form is the button up here that’s highlighted in red. That’s actually your specific online learning button. That will allow you to submit this document to that knowledge base learning server, where the learning will actually take place.
We don’t necessarily train every document that comes through Kofax. Sometimes when we’re setting up new installations and new builds we’ll do that for user-acceptance testing to get the knowledge base built up with documents, but typically when the validator’s seeing these, we’re not going to be learning every document. They’re going to flag the ones, if we have a PO number that comes in that Kofax doesn’t recognize but it’s kind of clear on the invoice to us where that PO number is, we’re going to have the validator … we call it lasso, but basically highlight that data point on the invoice and then they’ll flag that. Just click that specific online learning button and then Kofax will know to learn this document. That’s how the validator’s actually make the projects smarter as time goes on.
Okay, so now we’re getting into the good stuff here. The types of locators that we’re going to use to extract data off the invoices … there’s really four main types. There’s a lot of different configurations you can do within Kofax to pull data off of invoices. These four are the four that I’ve typically seen used. I’ll go through and explain each one and then kind of explain how I’ve been setting up projects recently when I build them in Kofax.
As I mentioned, over the years Kofax has definitely improved their software and the locators that we have available to us. We’ve kind of always had that first one here, the out-of-the-box knowledge base from Kofax that ships … basically has, I think, around 1400 invoice samples that have been submitted to it. It’s basically a grouping of invoice header information, so you have your invoice number or your PO number, you’ll have all your amounts, different amounts on the invoice that Kofax has already learned. You can you use that locator to populate those fields. You could actually add to that. That’s how the smart learning used to work, you’d actually add to those knowledge bases and grow them as you submit documents. That’s what we had for a long time and that worked great. We still use it.
The next one is the format locators. This is a little bit more of a manual locator. When you set this up, you are going to define usually a dictionary full of keywords that include … if we’re talking about invoice numbers, you might have a dictionary that would have terms like invoice number, or invoice num, or INV#, or anything that would resemble what a vendor might put on their invoice to identify the invoice number itself. Then Kofax looks for those phrases on the invoice and then it will grab the data. If you say check to the right of anything you see that says invoice number, and you find a number, it’s probably your invoice number. That’s how those locators work. They are a little bit more manual to set up, but they’re kind of a good last-line of defense if we can’t find any other fields a different way.
The trainable group locator is a newer locator that Kofax has come out with. It’s probably maybe five years old at this point, but this one was kind of a game changer when it came to extracting data. Similar to the out-of-the-box knowledge base that Kofax shipped with, you can train it, but you can define your own fields. We were a little limited with the out-of-the-box knowledge base that came originally with Kofax. You had a set number of fields that they were extracting, they already trained, and that was pretty much all you had. With the trainable group locator though, you can define all the fields you want to extract off the invoice.
They don’t have to be included in the out-of-the-box knowledge base. A lot of our customers on their non-PO invoices, they’ll have a routing code. You’ll have a company account combination that you might ask your vendors to put on your non-PO invoices. In the past we didn’t have a great way to extract that data smartly. We could create format locators and say put it in the attention line and then look for it there, but the trainable group locator gave us the ability to say we wanted to find a route code, and start training invoices on where that route code is, so that we can pick that up in the future. It gave us a lot of flexibility when it came to extracting different types of data and learning different types of data off the invoices.
The standard evaluator allows you to basically compare different locators. The three that we started off with here, these are the three main locators they would use when you’re building a project, to pull up invoice information. The standard evaluator allows you to compare those three. The way you can do that is either the first match, so you kind of rank your locators. If we’re going to say our trainable group locator is going to be our top one … if we find a value with our trainable group locator, we’re going to use that no matter what. If it doesn’t find something there then maybe check the out-of-the-box knowledge base from Kofax. Doesn’t find anything there, then use the format locator. The first one it finds, it’s going to use. That’s typically how we’d set up a project.
You can also compare the highest confidence. Of these three locators, which one is Kofax the most confident of, and then take that one. Typically I like to use the first match and then have our trainable group locator at the top. With that trainable group locator, since it is our exact samples that we’re passing through, if Kofax runs into one of those again and it’s able to kind of match the format of the invoice and we’ve already told it where to get all the values off of, we want to use that locator. That’s going to be typically our top one.
Some of our projects we’ve done recently, that’s been the only locator I’ve actually used, is just that trainable group locator. Kofax is able to learn all the fields we need to extract, and it’s worked great just using that one locator, but if you need to compare them, you’d use that standard evaluator. Those are the four main locators that I’d use for extracting invoice data off of the invoices.
I kind of mentioned briefly if Kofax can recognize an invoice … The way that Kofax does that, I actually had somebody from Kofax explain this to me once and they did a great job, I’ll try to explain it how they did, but when you train an invoice through the system, Kofax kind of looks at it as more like a thumbnail and then applies the rules accordingly. In the example I have up here, you can kind of see the first three invoices, they look the same. Then the last three invoices kind of look the same.
When Kofax tries to identify an invoice, it might see one that comes through that looks like these last three, it says, “Oh, well last time you said the PO number was up here.” It will know basically if it’s seen an example like this before and you’ve trained it that the PO number was up at the top, invoice number was right before it, things like that … it will go out and grab it from those locations. That’s how it’s able to identify the different types of invoices. It kind of looks at it from a snapshot, kind of far away, thumbnail view to classify and use different rules based off of how the invoice is laid out.
How does a system keep learning? After you implement Kofax, how does a system keep getting smarter over time? During the validation process, as I mentioned, that’s when the validators are actually going to flag the invoices for learning. If a new vendor or vendor invoice format changes and we get it in … they may have moved their invoice number, then the validators may need to change or to train those invoices again, but Kofax will then learn it. There’s really no maintenance that needs to be done with vendors invoice format changes. I also mentioned not all invoices are going to be learned. We don’t typically want to learn every invoice that comes through. If you do have a knowledge base that has thousands and thousands of samples in there, it does slow down the extraction a little bit, makes it a little bit longer to extract the data off. Typically the end-users don’t even notice that, because that’s all happening in those automated steps that we discussed, but it does take a little bit more server resources and things like that to extract the data.
We like to train the validators or end-users on how to train the system. We don’t want them submitting badly scanned invoices, or invoices that aren’t OCR’d correctly. If you have an invoice that it looks like it missed the invoice number, and then you try to lasso the invoice number to pull that number in and it’s can’t read that off the invoice, it’s probably not one you want to train, because it’s not able to actually read the data correctly off the invoice. You don’t want to train it to pick up bad data, basically.
Typically you only need to submit one or two samples per batch for an invoice type. If you have a batch that comes in that has the same vendor, 20 invoices of the same vendor, you wouldn’t want to train each one. You really just want to train maybe the first, or second if it’s missing fields. It’s not going to help you in that batch, either. Kofax is only going to apply the knowledge or the learning that you’ve flagged on the new batches that come in. If you’re training 20 samples, it’s not going to train for anything in that batch. It’s only going to train for the next batches coming in. You really just want to submit a few samples.
I do want to spend a minute or two talking about how to maintain your knowledge base. There’s a few tricks within the Kofax Project Builder on this. Out-of-the-box Kofax sets a default for the number of documents that can be stored in the knowledge base within the project. It’s set at 2000. A lot of our larger customers are going to hit that pretty quick. If you’re running through thousands of invoices a day, you’re going to hit those samples pretty quickly. I have another slide here I’ll show you in a second of where you can actually change that in the projects, so just to be aware of that. A knowledge base learning server is great, it works awesome, but it does not tell you when it’s full. If your project’s set at 2000, you’ll still see stuff in Kofax go through the learning server, but it’s not going to actually add to your knowledge base. You’ve got to be careful of that.
You do have the ability within Project Builder to review the samples that you’ve submitted, that have been submitted. You can clean up those samples as well, and I’ll give you another tip here when I get to the next slide about how you can more easily clean up those samples within the Project Builder. It’s not something you need to actively do, I would say. Maybe once every couple of months you might want to go in and just see what samples are in there. If people are submitting a lot of samples for the same vendors, same types of invoices, there may be some other problem with that invoice that you need to look at. It may not be a learning issue, it may be that Kofax is reading an O as a 0 or something like that, or an 8 as a 6, and you might need to do some other training on that. It might not be a learning issue.
Then if you do hit your max … you might not want to store 10000 samples in your project, because it does kind of slow things down. You can export these samples to what they call a generation folder, and that gives you the ability to still use them in your knowledge base, it’s just not part of your project. We can show you how to do that as well.
Okay, so here’s just a screenshot from within Project Builder, the advanced online learning options that you have. Really two important things on here. When you set up your project, you have the ability to apply just one group-by field for all your learning samples. Basically any field that you identify in your … if you have invoice number, vendor, PO numbers, things like that, you can pick any of those fields to group your samples by. I would definitely recommend using vendor. If you have a vendor number that you’re capturing, I would recommend using that as your group-by field, so when you go in to manage your samples, you can sort them all by the vendor number. I don’t know what this defaults to, but I know it’s not vendor, and if you don’t set that it’s hard to manage your samples on the back end. It can be changed, but you’ll kind of lose that for all the samples that are out there.
Then the other thing that I had mentioned was the amount of documents you can store. Down at the bottom there highlighted in red, typically I think that starts around 2000. I usually move that up to around 5000 when we start an implementation, just to be able to collect more samples and make sure we don’t run out within the project.
A typical training process, how do we train our projects as we’re implement Kofax? The 80/20 rule definitely applies. 80% of your volume is going to come from 20% of your vendors. If you identify those high-volume vendors, you want to run those samples through. Typically as we’re building the project, before we even get into any testing with our customers, we’ll want to get some invoice samples from them for those high-volume vendors. I usually like to ask for three to five invoices per vendor. The reason for that is I’d like to train maybe one to three invoices for the vendor and then have a couple extra ones to run through as well, just to make sure that the extraction’s working properly. If you train Kofax on a sample and then you run that sample through again, I would expect it would get a perfect extraction rate, but we want to try to run some other documents through that it hasn’t been trained on.
After we run some of these through initially, for our high-volume vendors we might want to check to make sure that the extraction rates for those vendors are good, that we’re not missing fields that people are going to have to validate thousands or touch thousands of fields as invoices come through. We want to eliminate that as much as possible.
We do have the ability to create what’s called a sub-class within Kofax. It’s kind of a template for high-volume vendors. If we have a vendor that we’re just missing a field on or that we need to apply kind of a special rule to, I mentioned earlier like the 0 and the O, or if some vendors start an invoice number with INV in front and you want to strip that off, we can kind of build in some of those rules for those vendors as well. At that point we typically turn the solution over to the customer for user acceptance testing. At that point, that’s when they’re really going to start training the system. Any of the smaller vendors that we didn’t bring invoice samples in for, when Kofax sees it for the first time, they may need to be trained. That usually happens during UAT to build up that knowledge base within the project.
You don’t have to train for each vendor that comes in, necessarily. A lot of vendors might use QuickBooks, and with QuickBooks, the invoices are going to look very similar. Even though it’s a different vendor, if you flag the invoice number in one QuickBooks invoice, it’s probably going to be in the same place in the same invoice. You don’t have to train for every single of invoice, and if invoice layouts are similar, Kofax will still be able to get the data extracted off.
I think that’s about all I had for today, kind of just give an overview of how the learning works within Kofax, help you dig in a little bit more to set up your projects or extracting data, kind of optimizing your projects to use those locators to get the data you want, and to make sure that it’s set up to keep learning over and over again. This was part of our summer webinar series, so we do have other webinars that will be posted up on our website. Check that out. There’s a lot of other imaging webinars as well up there. If you’re a Lawson customer, we have tons of Lawson webinars up there as well.
We’ll take some time, I think we probably have a few questions. I’ll go ahead and answers those questions.
Speaker 2:
First question is, what if the same data is on the invoice in multiple locations? Will Kofax get confused?
Brian Ayres:
Not really. A lot of times the invoice number might be at the top, it might be at the bottom as well. If you have a validator that one’s picking it from the top, one’s picking it from the bottom, the system will still keep learning, and it will actually just be comparing those two results. It will always return that result, it might just take a little while for it to build confidence about which one it should be using. Once that field on the validation form is green and you’ve trained it a few times, then you don’t even need to train it again. Once it determines which one of those it wants to use, you don’t have to train it anymore.
Speaker 2:
Great. Next question is, when a new vendor is found on an invoice, is there any set up needed?
Brian Ayres:
No, so if a vendor either changes their format or if you guys start using a new vendor, as long as the learning is set up and the locators are able to be trained, there’s nothing you really need to do to the project. If it’s a new high-volume vendor, you might want to review to make sure that we actually are extracting all the fields off there correctly, but yeah, nothing that you really need to do. That’s kind of the nice part about this solution.
Speaker 2:
Does the learning server play a role in helping clear up misclassified documents, such as if a statement is scanned in?
Brian Ayres:
You can use that if you want. The learning server, the contexts I’ve kind of been talking about with it was just for extraction. You can use it for classification as well. If you want to classify certain types of documents, yeah, you can do that as well and train Kofax on classification as well. This was focusing much more on extraction, but yes, you can do it for classification as well.
Speaker 2:
Okay. I think that’s all the questions we had. We haven’t had anymore submitted, so thank you everyone for joining.
Brian Ayres:
Awesome. Thank you very much. Appreciate your time today.