Alex Lindsey:
Hello everyone, and welcome to another Webinar Wednesday with RPI Consultants. Today we are going to be talking about advanced data capture with Brainware by Hyland. But before we do, we’re gonna cover a few housekeeping items. First and foremost, this webinar will be recorded. I will be posting this on YouTube and on our blog on our website. For those of you dialing in today, we are gonna send out a copy of this slide deck that you’ll see today for any type of further review you want to do.
We also have a moderator standing by, so if you guys have any questions throughout the presentation, please go to the webinar box labeled questions, and insert your question. We will be happy to handle those at the end of the presentation.
Additionally, if you have any ideas for more webinars, we can continue to come up with as many as possible. But if there’s something you specifically want to see or want to explore, we’d be happy to do another webinar for that, and please just put that in the comments section as well.
And finally, we have one more webinar today. It is for our PROFORMA product. It is a great software for management. If you haven’t seen it before, I encourage you to join that. There’ll be a list of … there’ll be a site where you can go at the end of the presentation, so if you’d like to join that webinar, we highly encourage it.
So let’s go ahead and get started. My name is Alex Lindsey. I’m a senior solution architect with RPI Consultants. I’ve been working with the ECM products, OCR products for six plus years now, so I’m very familiar with a lot of those. I specialize in accounts payable solutions, as well as non-payment solutions. If you’re looking to do something weird with the software that you own, please come talk to me.
Michael Madsen:
Hello. My name is Michael Madsen. I am a senior consultant with RPI. I’ve been a consultant for around five years. I specialize in manufacturing, higher ed, and accounts payable departments.
Alex Lindsey:
A little bit on the agenda today. First and foremost, we’re gonna talk about us, because we’re narcissists, and that’s just what we do. But we’ll cover a lot of who we are, what we do. Then, we’ll jump into Brainware and kind of how it can help you. Some unique scenarios, because it is a very unique product in the fact that it can do a lot for you. Then we’ll show a demo that Mike put together of the verify tool that is part of the Brainware Suite. Then we’ll cover some additional features, and we’ll close out with a summary and open up for questions for you in the audience.
Michael Madsen:
So, a little bit about RPI Consultants. We have around 80 consultants scattered across the United States. We have offices in Tampa, Baltimore, and Kansas City. Alex and I are on the ISTS imaging team with around 20 consultants in Kansas City. We work with Kofax, OnBase, Capture, Content, and Lawson. So, we can help you out with any of those things. Some of the things that we do are integrations, Go-Live support, managed services. We can also help analyze your current workflow processes to enhance your productivity there.
Alex Lindsey:
We also offer managed services and remote administration solutions as well.
So, kind of jumping into what Brainware is. You’ve probably heard about it. If you are a Perceptive Content customer, you are probably very familiar with what Brainware is, so you may already be using it. Perhaps you’re an OnBase customer, and you’ve heard all the good news about Brainware, things like that.
So there has been quite a few changes within the ECM space. Perceptive Content and Brainware rolled up under the Hyland umbrella. And, it’s important to note that Brainware is the go forward OCR engine for the OnBase customers. So no matter where you’re approaching this from, I think there’s something for everyone is this presentation.
Michael Madsen:
And to give a little bit of background information on what Brainware is, it’s just a powerful OCR technology. So you can read documents into Brainware, it can extract the data from it, and then it can export it to pretty much any ERP or ECM you want to use it with. And also, there’s reporting, so the visibility reporting of Brainware will kind of give you some statistics about your Brainware usage.
Alex Lindsey:
Field specific stuff. If you’re getting a vendor ID correctly or not. Very specific things. It’s a great reporting tool.
So when you’re considering purchasing Brainware, for instance, or if you’re just exploring other OCR technologies, here’s a feature deep dive of kind of what best use case scenarios for Brainware technology.
So essentially, it is a great front end OCR system to basically capture anything. It says invoice here, because it’s used a lot with invoices, but it can capture any kind of document types or class that you guys have. So essentially, you front end that. You take your manual processes and you try to automate them with the Brainware engine. So you scan in documents, or input them or email them. However you want to get them in. And Brainware will essentially go through and extract data off of them, and validate that information, and basically push it to wherever you want.
It can work with a bevy of host systems, so again, it’s very configurable and customizable in the sense that we can talk to a lot of different systems. It doesn’t have to be an ERP. It doesn’t have to be in that student information system, or an EMR. It can be a custom data base, if you want. It can talk to a lot of different things.
Michael Madsen:
It also has exception routing. So if you have any issues within verifier while you’re verifying documents, and you need to get out of Brainware, there are a lot of invalid reasons that you can use to release your batch that’s in Brainware so that you can move it to your exception queues in your next system.
It also deals with complex data integration, so there’s no real standard. Well, we’ll go into some of the standard items that can be configured in the next slide, but it can be configured to any kind of customization that you need. So you don’t have to stick to those standard builds.
So to go through some of those standard solutions, we have Brainware for invoices, Brainware for transcripts, Brainware for remittance processing, and Brainware for bills of lading. So to give you kind of my idea of what that means, like for invoices, we may have PO numbers, and we can fit that PO format to match what’s on your invoices, and then further validate that PO against views that you may use in your other systems. And then for something like remittance processing, we could validate credit card information, and even process credit cards within the system.
Alex Lindsey:
Yeah. It also handles non-payment solutions as well. So there are a number of clients out there right now that are using Brainware for one of these standard solutions, but they’ve also developed a project within Brainware to use it as a mail room solution. So as documents come in from anywhere, essentially, Brainware was trained to identify those document types and route them to the appropriate places that it needs to go, and hold data along with it so that it can be handled in whatever system you guys want to push it to.
Another good example, because Mike mentioned credit cards, so another good example is a customer that is currently using it for a non-profit scenario, where people are donating money and inputting credit card information onto slips of paper, essentially. So Brainware is being used to extract that information, and bounce it against their database so that they can then store that.
What once was a very manual process is now a very automated process. And this can be used in any kind of vertical, really. So it’s not specific to healthcare or manufacturing or retail. Brainware can be used in a lot of different departments in whatever industry you’re in.
So when it comes to data validation and some of the integration, there’s a good amount of data in and data out, right? So the data in part, so we’re basically going to bounce the extracted results, and we’ll go through how that kind of works in the next slide. But all the results that were OCRed and extracted off of your documents, we want to make sure that it’s correct before we send it into a work flow process, or your accounting system, or student information system, right? So we can bounce that data, or bounce the extracted results, off of an accounting system, an ERP, electronic medical records, an HRIS, and banking systems, so that you know that when the document, because again, Brainware and OCR can be kind of what they determine a fuzzy logic situation. You want to make sure that the data that’s being pushed in to your system is correct. So that’s where the data in kind of plays in.
Michael Madsen:
And then at the end, of course, we have our export. So when you’re exporting data in Brainware, generally the default method is just through an XML file, and that XML is totally configurable based on how you need the data to be built out. But you can also use web services, or really any other kind of export process that you need to use with your system. But generally, it sticks with the XML. But again, customize however you need.
So this is a little bit kind of an overview of the Brainware process. So obviously, the first step is getting the document into Brainware, and you can do that either through scanning, email, or file import. Once that document is imported into Brainware, Brainware will create a batch using that document, and that batch will be assigned a state ID. The state ID is what Brainware uses to determine where in the process that batch is.
So once it pulls the document in, one of the first steps it’ll hit is that OCR and extraction. So this is gonna be where it classifies what kind of document it is, and then it reads through that document to pull the data that we configured in Brainware into our verifier, or if the process is straight through, then that’s what will be exported.
Alex Lindsey:
And based on the document type, too. There’s a certain amount of fields. So if you’re doing a transcript document, or remittance document, or an invoice, there’s a certain set of fields that needs to be extracted off of that. And with those fields, you can set a confidence level, essentially. So if it finds a value and it validates it, and it’s confident that that’s the value that it needs to be, then it can go straight through directly into your system to the validation and the export. If it doesn’t, it’ll stop in what we call the verifier. At this point, the verification process happened. This is where your users will use either a desktop client or a web client to essentially verify the documents.
In the case of invoices, which is a very common use case for Brainware, users will go in, and perhaps the purchase order number was not extracted off of the document, or it just didn’t look right, or it didn’t even fit your accounting systems purchase order number structure. At that point, the user will go in, correct it, or select an invalid reason to get it out, and you’ll see some of this in the demo as well. Or it could be another situation where you have perfect extraction results, but you couldn’t actually validate the data. For instance, a non-PO invoice. Well, I see that it’s this vendor, but I don’t actually have a record of that vendor in your accounting system, perhaps because that vendor wasn’t created within Lawson. So at that point, the user could then do an exception or select the correct vendor. After that, it’s gonna go through its final validation, where it’s gonna check and make sure that everything is good and then be exported. Like Mike said, through typically an XML, but with DSN web service can be used as well.
Along with that, the document itself can be sent as well, along with the associated meta data. It’s important to note that that XML can be structured in a number of different ways. There is a just out of the box format, but all the times that I’ve worked with it, it’s never been just the out of the box format. A lot of times, customers come to us with hey, we’d like to do additional work ups with this, can we push this into the export so that when It gets into my accounting system, or within OnBase, or Perceptive Content, I have this extra value that I can then route on?
We’re gonna jump into the demo here. Just a short video.
Michael Madsen:
Hello, my name is Michael Madsen with RPI Consultants, and I’ll be walking you through this virtual tour of Brainware by Hyland’s Verifier. This will just be a very high level quick video, just to kind of give you an idea of what Verifier looks like.
So I have Verifier opened here, and you can see that I’ve got my list of batches in this window. Batches are just the groupings of documents that are moving through Brainware. Some things to point out while we’re on this screen, just some of the columns here. We have state. The state number is the number that Brainware assigns to the batch so that Brainware knows where in the Brainware process that batch is. So when it comes to Verifier, the main thing that we’ll be concerned with is just the 550 states, and generally, your Verifier will be configured just to show the 550s.
So 550 means that the batch has been extracted, but it’s stuck in the verification stage, awaiting user intervention to verify some issue fields where either an item wasn’t pulled meeting Brainware’s confidence rules, or something couldn’t be validated, like if a PO number was pulled, and that PO number couldn’t be successfully validated against one of your data base reviews.
The last user column outlines who the last person was that opened the batch, and then the last access column is the date and time that that batch was last accessed by that user.
The last thing to note about batches is that batches generally can be configured to have as many documents as you want inside of the batch. In this example, each batch only has a single document. So there’ll be one batch per document, but that can be configured however your business requires.
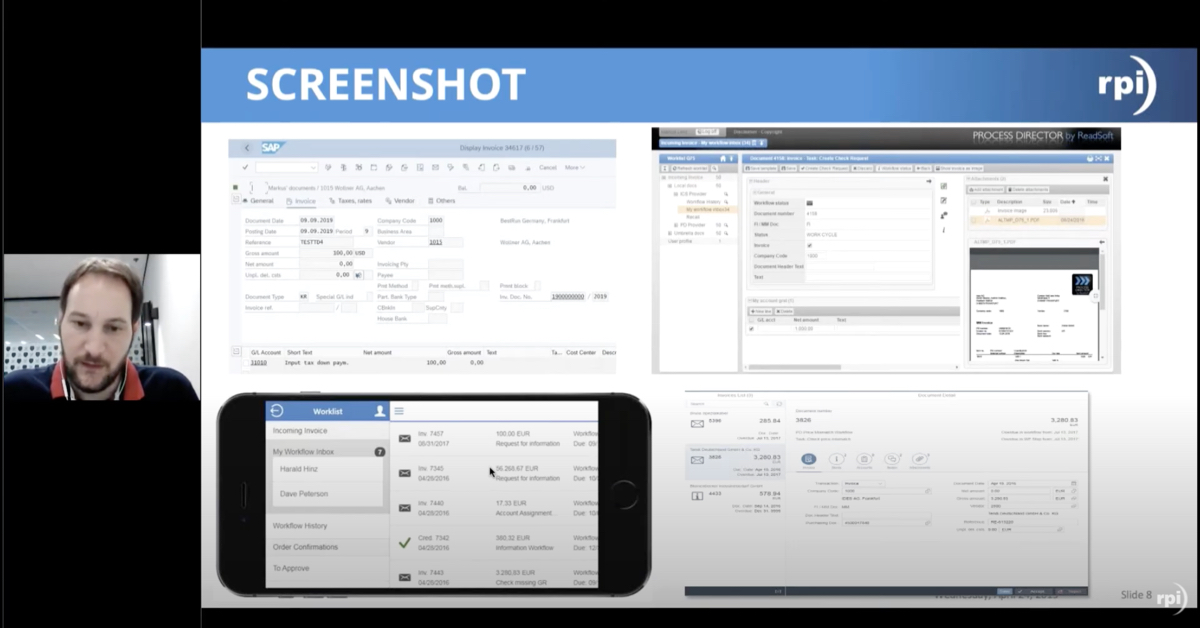
So I’m gonna go ahead and open up this batch, just by double clicking the line here. And when we’re inside of the batch, you can see on the left side, I have the image of my invoice. On my right side, I have all of my fields configured in Brainware to pull from that invoice during extraction. And then down at the bottom is where I’m gonna be able to find my error messages in case I’m in a field that is errored.
So our main focus will be on the right side of the screen here where we have our extracted fields. Most of the fields are green, which is good. When the field is green, it just means that Brainware was confident that what it pulled matched with what was on the invoice. Anything in red is what we have to look at and correct before we can export the document.
So to give you an idea of how some of this works, like you can see over here, we have these highlighted areas. When I have my clicker or my cursor inside of one of these fields, I can see the highlighted sections where Brainware cloud may be able to pull that data. And then when you see something like this, where it’s in this red box, that’s where it actually pulled the data from. So this is where it decided it found its data and pulled it into that field.
To note at the bottom here, right above this typed in section here, I have an image that’s kind of a blown up section of where it was pulled from the invoice, just so that it’s a little bit easier for me to see. So I don’t necessarily have to zoom in on the invoice, but if we do need to zoom in or zoom out, we can still do that with this section up at the top here. I can also rotate the document in case it was scanned in sideways or something like that.
So whenever I’m clicking through my fields here, I can get an idea of where Brainware is getting that data. Now, not all of the fields will act that way. A good example is the vendor fields. This vendor information is actually pulled from my PO number. So Brainware uses that PO number to query against a view that will also include my vendor data. So whenever this PO is entered and validated, that’s what inputs the vendor information here. And that’s also why I can’t really see when I click on these fields what’s being pulled from the invoice because of this.
So to release this batch into my next process, I have to fix all of my issue fields. So in this one, you can see that most of my header details came in normally, and then my line details here at the bottom also read in, and our totals are matching. So everything should be good on this invoice except for the invoice number.
So if I want to fix this invoice number, I can click in the field and then come down to the bottom of the screen to read what the error message is. This error message involves a lack of a learn set for this invoice number, so this may be an example of a company has received new invoices from a new business that they’re working with, and maybe those invoices haven’t been fed in to Brainware for Brainware to learn the invoice format. So you can see here where it zoomed in on that field that the number that it pulled, which is here, matches up with what’s on the invoice. So the number is correct, it just wasn’t able to validate against some invoice formats that have been entered into Brainware through learn sets. So in this situation, all I have to do is tell Brainware yes, this number that you pulled is correct, and we can release this batch.
So when I have my invoice number, or my cursor inside of my invoice number field, I can just hit enter on the keyboard, and that will tell Brainware that it’s okay. It switches it to green and it asks me if I want to release the batch. I’m gonna go ahead and click no here for just a minute so that we can talk about a couple other things.
So another item to point out up here is the invalid reason section. So I have a lot of different options to choose for an invalid reasons. And an invalid reason would be something that I would use if there was a PO number on the document that I was reading through Brainware that either wasn’t in one of my views yet, or for some reason, the Brainware couldn’t validate it. So I need to push it through Brainware so the users on the other end can fix whatever issue I’ve run in to. In that scenario, I would select missing or invalid PO as my invalid reason, and whenever I select that and hit enter, then if my PO field were red, it would immediately switch it to green. It no longer cares about what PO number I have entered in there. And when it moves on to my next system, that invalid reason will be included in the XML that Brainware sends during export. So, that way the document could wrap whatever exception queue it needed to go to to resolve whatever issue it had.
But in this scenario, my invoice is good to go, so I’ll just hit enter. It will pop up with my message letting me know that my batch is complete, and I’ll say yes to allowing it to release. When I click yes here, it basically just moves it to the export portion so that it can be exported into my ERP or ECM. After it’s exported, or after it’s released the batch, Verifier will just move me to the next batch in the list that needs verified. So then I would fix my issues on this invoice, move that forward, and just continue the process until all of my verification is done.
And that’s essentially just a really quick overview look at what Verifier looks like and what you can expect when you’re inside of Verifier.
Alex Lindsey:
All right. Thank you Mike for that video. Again, that was a great example of one of the standard solutions, really, where Brainware was used for invoice processing, purchase order, invoices, and things like that. So just keep in mind, when you saw that Verifier form, that can be any number of documents, doesn’t have to be invoices. It can be insurance claims, it can be remittances, it could be, again, for a non-profit donation slip. Things like that. And the form could look completely different to however you want to do it.
So some additional features with that, again, like I kind of mentioned, it does have enhanced and flexible configurations. So it can be catered to kind of any business that you want to send documents through. One caveat, make sure that the document images are clean, obviously, but if they are clean and we have data we can validate against, Brainware could work for you.
For invoice processing specifically, the line item extraction and the line pairing for purchase order invoices is very good, actually. Within the latest versions, they’ve actually improved that process quite a bit. So if you want to do invoice processing with it and you do have a large number of purchase order invoices, it’s a great option for you.
Michael Madsen:
And some other items to mention are Brainware’s learn sets. So learn sets are just a way to help you configure Brainware for your business. So if you picked up a new business and you’re receiving new invoices or any other kind of new document, and maybe there was an ID that you were looking for that moved locations or was in a new format, you can use learn sets to read in these new documents to, again, help configure Brainware for these new documents so that it can pull them in the future.
Exception handling we’ve gone over a few times, and it was kind of covered in the video with the invalid reasons. So if you set the invalid reason within Verifier, then that will allow you to release that batch into your next system so that you can do whatever kind of exception handling you need to on that document.
And then finally, advanced validations. That’s what we’ve been talking about when we’re talking about like if we take a PO number and validate it against a PO view that’s been built outside of Brainware. We can validate data that way.
Alex Lindsey:
One other thing to mention too is the reporting. We don’t touch on it too much here. We can do a demo certainly for the visibility reporting tool. It is actually a fantastic reporting tool. UI is very good, and it does show specific field extractions. So in the example of invoices, for instance, you can see your top 10 vendors, and you can see which fields are constantly being missed. Invoice date is being missed constantly. So why don’t we do a learn set to basically make sure that we capture that and improve your extraction results.
So some of the benefits and considerations. It is highly scalable. When I mean highly scalable, I mean it can handle a large volume of documents. So one client that we know of is using Brainware for tax document preparations. So if you can imagine, January through April 15th, there is a large number of documents coming into this firm. They are using Brainware to basically scan, email, import in documents. Extracting tons of information off of those documents, bouncing it off their whole system, and pushing it into their work flow processes. So it can handle millions and millions of documents on a level that’s pretty great actually. So you consider the architecture and things like that, it’s highly scalable. It can handle peak volumes and low volumes without a lot of fuss.
It is also, when I say powerful OCR engine, it can be very flexible in the fact that it can do a HR department, accounts payable department. It can handle quite a few different departments, and you just basically train it to do these specific document classes that you need it to do. And again, for the users that have to go in and verify, you have options. So you can do a desktop version of the Verifier, which you kind of saw Mike demonstrate, or you can do a web Verifier option as well.
Michael Madsen:
And then to go along that same vein of scalability, Brainware is very customizable, so you can make it meet, just like what Alex was saying, any kind of business structure you need. It’s licensed by page count, and then to go along with that, the return on investment for Brainware really scales up the more documents and users that you have.
Alex Lindsey:
So that is, in general, what Brainware is. If you guys have any questions, let us know.
Speaker 3:
Yes. Thanks, guys. We do have just a few questions. And anyone who wants to submit a question, please use the question pane inside of the Go To Webinar meeting window to submit them there.
Okay. First question is it would be great if you could do a webinar on Visibility in the future. Alex?
Alex Lindsey:
I actually think we can do a webinar on Visibility, or I actually think we can do just a short video. Oh, we have one? Oh that’s right. We do have one. We have one. We can send you the link along with the slide deck.
Speaker 3:
But if there’s anything else you’d like to see after that, we’re happy to put together more information.
Alex Lindsey:
It’s important to note that’s a separately licensed product, too. Sometimes clients don’t know that. If you’re an OnBase customer right now and you want to have that reporting capability, as far we know, right now, Visibility is a separately licensed product.
Speaker 3:
Can Brainware have multiple documents per batch?
Michael Madsen:
Yes. So you can configure your batch based on however many documents you want inside. In the video, it was just an example of just having a single document in a batch, but that can be scaled to whatever you need.
Alex Lindsey:
So another good example, like an electronic medical record where you have different document types that are coming in. So the first three pages of the batch can be this document type, second two pages can be this, last five can be this. So you can have that all in one, basically, batch.
Speaker 3:
With newer versions of Brainware, can you delete the page in a document or move pages around?
Alex Lindsey:
No. You can’t delete the pages themselves. With Brainware, you’re essentially just getting the page of the document itself, which can have multiple pages. So if you have a page in there that’s not correct, what we typically recommend is to void that document and to send that into a workflow process, or basically a work flow process so you can contact that vendor and tell them to kind of get their butt in gear and send you the correct document.
In terms of moving pages around, again, if it’s not something … if it was scanned in with let’s say the last page, things like that. The engine’s still gonna try to find the specific values for that document itself, but it may be a little confused if it’s used to seeing maybe like a cover sheet or something like that.
Michael Madsen:
We’ll say in newer versions, you can do document splitting in Brainware now, so you can split a document and then void part of it.
Alex Lindsey:
Yes. So if you needed to … yeah. If you accidentally scanned in two documents that need to be split, that’s an easier solution, to basically split it up.
Speaker 3:
All right. If multiple documents are in a single batch, and one document requires verification, are all of the documents held up in the batch until the items are finished and verified?
Michael Madsen:
Yes. So essentially what happens is because they’re all part of that batch, that batch shares the state number. So when it hits the state 550 requiring verification, that means that anything that’s inside of that batch will halt in Verifier. Once you verify the single document that needs to be processed, then it will release the entire batch.
Speaker 3:
One question around a product. Is data capture for transcripts a more specialized version of Brainware?
Alex Lindsey:
No. It’s one of the favorite solutions. So for transcripts, it’s-
Speaker 3:
Data capture is an old-
Alex Lindsey:
Oh, data capture.
Speaker 3:
-is an old product that is no longer around. However, there is a new solution for Brainware that is transcript solution.
Alex Lindsey:
For transcript processes. So if you do have data capture, and Perceptive as one of the old solutions, there’s a new transcript solution, so we mention is one of the standard transcript solutions that comes out of the box there. There are a lot of clients using transcript processing with Brainware integrating directly with Perceptive Content, and it can also be integrated for any SaaS system that you may have set up or solution you have set up in OnBase as well.
Speaker 3:
All right. Thanks guys. Can Brainware do any workflow or approvals.
Alex Lindsey:
No.
Michael Madsen:
No. That’s gonna be whatever you move it into like OnBase or Content. Brainware won’t do any kind of approvals or anything like that. The entire workflow of Brainware is just that state movement. So once it exports out of Brainware, that’s where it would actually enter your business workflow.
Alex Lindsey:
Or if you have Lawson APIA, that’s another good example of an ERP specific one that you can push into to handle those.
Speaker 3:
Can batches be secured from each other so certain users can process certain batches?
Alex Lindsey:
Yes. So essentially there’s a batch user that can be, upon capture, that can be specified. So if I’m a Verifier user, then I can only see a specific batch number that I’m responsible for.
Speaker 3:
What is the level of effort to switch from using Brainware with Perceptive to using Brainware with OnBase?
Alex Lindsey:
I mean really, there’s really no difference. You have the same host system, so accounting system or student information system, or EMR, anything like that. If that’s not changing, all that’s really changing is the integration on the back end. If you still require all those same fields that are gonna be pushed into OnBase, at that point, if you have Brainware, keep Brainware. Depending on your version, obviously. We want to make sure you have the most current version. But that still shouldn’t affect the export coming out.
Michael Madsen:
Yeah. And everything that’s been captured in Brainware is configured in Brainware. So it’s not really gonna change the configuration within Brainware. The only difference may be like what Alex mentioned, the export process. If there’s any difference in how you need to ingest that information.
Alex Lindsey:
So one good example would be Brainware for invoices with Perceptive Content. There are a set of scripts that were used that were labeled BW this, or IC this, or if you’re on the latest version you’re using, Perceptive connect run time. Essentially, we would just turn those off and the configure a new connector or OnBase, essentially, to push the same values over there.
Michael Madsen:
Right, and worth mentioning that, just in case it’s not clear. The product Brainware itself is not changing substantially immediately. So, if you already own it, the next update will have some Hyland branding, but the product itself will continue the same.
Alex Lindsey:
Good point.
Michael Madsen:
All right. I think that’s it. That’s all the questions we have. Thank you guys.
Alex Lindsey:
Thank you guys for attending Webinar Wednesday. Again, we have one more today if you go to the website here, rpic.com/webinars, you can join the one for PROFORMA. It’s a great tool. I love it. And if you have any other requests or questions about this, please feel free to reach out to us at RPI and rpic.com, or call us. Thank you guys very much.
Michael Madsen:
Thank you guys.